
As speech-language pathologists, we use tests to help us make decisions about whether or not individuals have speech and/or language disorders. Sometimes we use standardized tests to help us make those decisions. How do we pick the tests? Well, we need to make sure a test works for the age and language background of the person we are testing. We want to make sure a test addresses the areas of concern that have been raised by parents and teachers. We also want to make sure it has high estimates of reliability and validity. These are important test statistics that we need to know about and consider when selecting tools to use during a speech-language evaluation.
In order to justify the use of a test you need high estimates of Reliability AND Validity.
Let’s start with reliability. Reliability is the consistency of a test.
In order to make inferences about an individual’s abilities based on their performance on a test, we need to know that the test is consistent in its measurement. If our tool is not consistent, we can’t use it to inform our diagnostic decisions. Thus, reliability is necessary but not sufficient to justify inference based on test scores.
Let’s talk about ways we can look at test consistency. There are a number of ways to measure reliability.

Split-Half Reliability
We can measure split-half reliability, which says we’re going to take the first half of the test and the second half and see how consistent responses are on the two halves. For tests that are structured with easiest items first to most difficult items last (like most speech-language tests are), we might take the even items and the odd items to look at split-half reliability.
Inter-Rater Reliability
For inter-rater reliability we look at consistency between different people administering the test. So, I’m going to administer the test to a child. And then I’m going to ask one of my colleagues to do the same. Next, we’re going to look at the consistency between the scores. So that would be an example of inter-rater reliability.
Test-Retest Reliability
This is the same rater administering the tool twice. I’m testing Johnny today. Then I’m going to test Johnny again in five days and see what the consistency between the scores is.
In reality, test developers look at this on a larger scale and not at the individual level. For example, looking at the PLS-5-Spanish, we see that there are estimates of Test-Retest Reliability for different age ranges with roughly 40-80 individuals in each study. The estimates of reliability are correlations between the scores on the test and the scores on the retest for the individuals in the study. On that particular test, the estimates of reliability range between .85 and .92, which is considered good consistency.
Why isn’t the correlation a perfect 1.0?
There is error in every test we give. It can result from biased test items, lack of exposure to testing situations, lack of understanding about what is expected, distraction, feeling poorly,… any number of things. Thus, a given individual will not perform exactly the same with the same test time after time. These are important things for us to remember.
- There is always error in tests.
- Tests can help us make diagnostic decisions.
- Test scores are not diagnoses.
So, we want to pull those Examiner’s Manuals out and take a look at what the reliability is to see if this is a tool we can have confidence in.
We also need to remember that reliability isn’t the only thing. In order to justify the use of a test, we actually need both reliability and validity. Reliability is necessary but it is not sufficient to justify inference based on test scores.
In other words, we can say that we have to have a tool that is consistent, but the fact that it’s consistent does not tell us what we’re measuring or that it’s measuring what we think it’s measuring. So our high degree of consistency doesn’t ensure that our inferences are defensible, but it is one important element for that process.
Validity is the other piece of this puzzle. Validity tells us whether a test really measures what it is intended to measure?
Is this measuring receptive language skills? Is it measuring semantic abilities? Whatever the goal is, we want to have some sense that the tool actually measures that thing.
There are several ways to estimate validity as well.
Content Validity
Content validity is often provided by experts in the field who judge whether the items that make up the test match the goal of the test.
Face Validity
This is another form of content validity but is often judged by the general population as opposed to experts in the field. It’s like asking, does this test seem to measure what it says it measures?
Criterion-Related Validity
Criterion-related validity explores the relationship between test scores and things of practical importance or related outcomes. For example, the ACT and SAT are tests taken to help colleges decide whether students are good candidates for their university. While there are plenty of studies that say things like high school grades are better predictors of college success, looking at ACT scores correlated with college success measures is an example of criterion-related validity.
Construct Validity
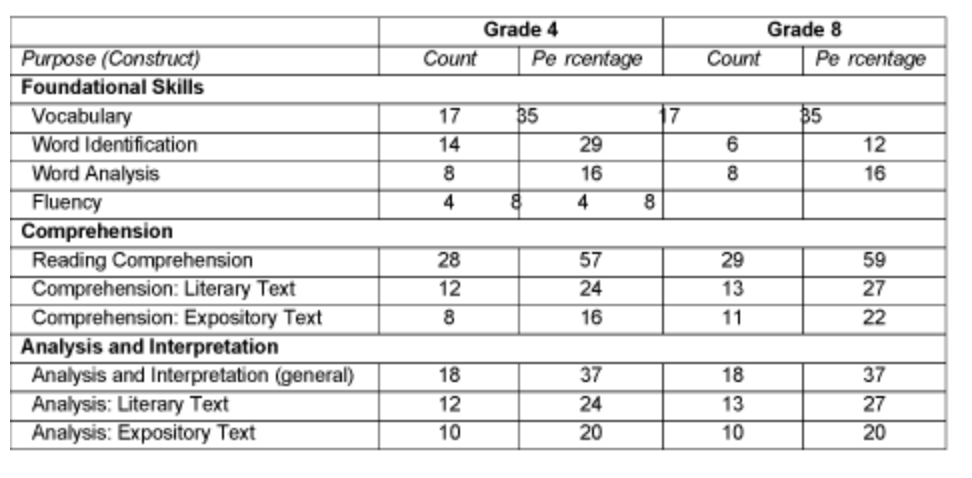
Construct validity gives us an estimate of the degree to which a test measures the underlying theoretical construct it purports to measure. It looks at the different types of questions on a test and categorizes them to explore how much weight is given to each area. Here is an example of a chart that explores how a test weights different areas of content.
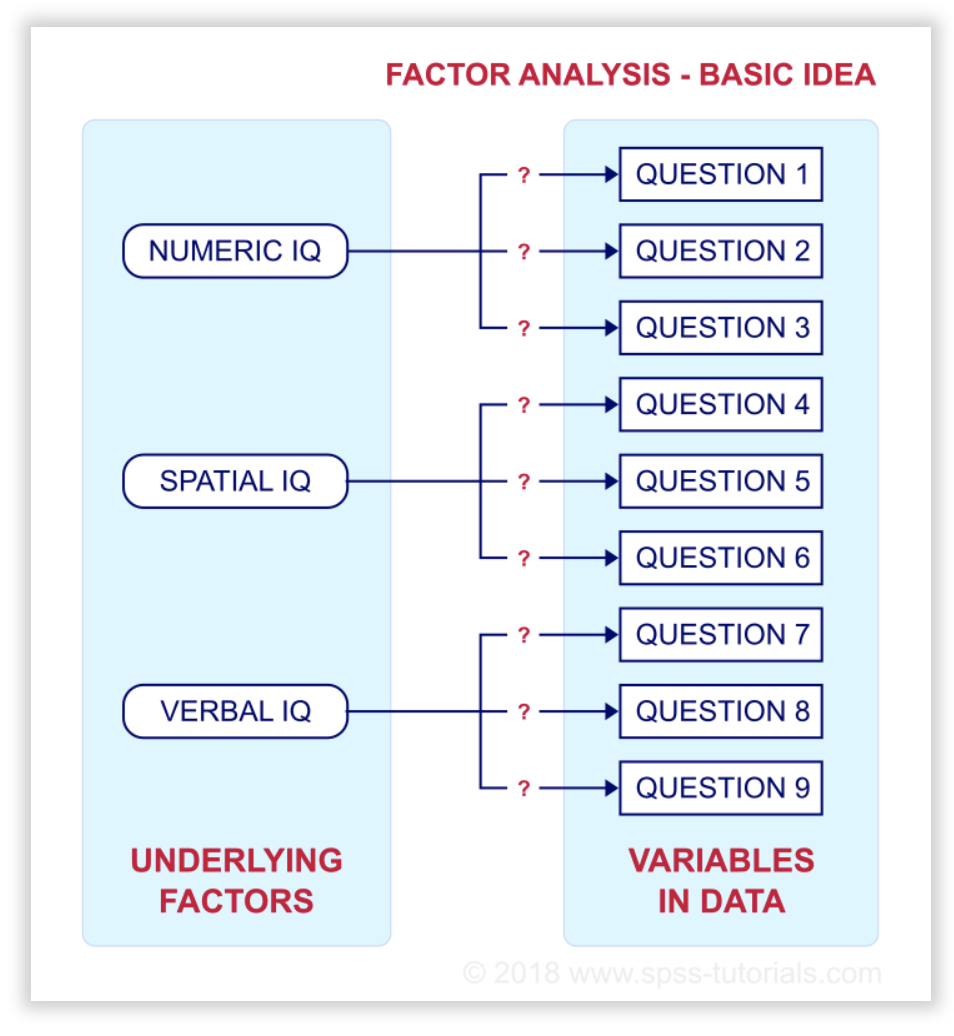
Factor loading is a statistical analysis that is used to explore how items group together to explore the similarities and differences between them. This is another way to estimate construct validity.
Here is an example from SPSS of what factor loading looks like.
What Levels of Reliability and Validity are Considered Acceptable?
Estimates of validity are often not as high as reliability estimates are. This makes a lot of sense when we think about it. Reliability is consistency on the same tool. Validity is consistency between different tools that attempt to measure the same thing. There is some variation in what is considered acceptable. This source says reliability of .80 is considered good and anything below .50 is unacceptable. Here is another source that offers general guidelines for interpreting reliability estimates.
For validity estimates, generally speaking, the higher the correlation, the better the tool. You will also see variation in the interpretation of validity measures. Here’s a validity interpretation scale that feels quite low to me. This comes from the same source as the reliability chart above. You can see the big difference between interpretations of reliability and validity estimates.
Let’s look at an example of a validity estimate from the field of speech-language pathology.
Here is a field-specific example for us–one of the validity estimates included for the PLS-5-Spanish is the (adjusted) correlation between scores on the CELF-P-2-Spanish and the PLS-5-Spanish. These are both tools that purport to measure expressive and receptive language skills in young children who have been exposed to Spanish in the home. As we know, the two tests go about this process very differently. So, while we expect some correlation, we don’t necessarily expect it to be super high. The adjusted correlations reported ranged from .67 to .78. In other words, there is a high, positive correlation between scores on the PLS-5-Spanish and the CELF-4-Spanish.
Understanding reliability and validity is a small but important piece in the complex process of testing language skills.
We have to remember the complexity of this thing called language that we are measuring. It is a very complex construct to measure and different people have different ideas about what is important to measure. This is also a reminder to us that there is no perfect way to measure language and no perfect tool to help us do it. And that’s why we use standardized tests as guides to help us make diagnostic decisions, but not as the be-all-end-all.
Resources
Be sure to check out our handy tool for exploring diagnostic accuracy in speech language tests too.

